DIGA録画番組名一括変更を支援するツール群の説明補充
DIGAの番組名を一括変更するツール群を2月~3月頃に作成し、日々使っております。ずっと問題なく使っていたのですが、先ほど使った際にエラーが表示され、調べたところ、説明不十分な点に気が付きましたので、説明を補充しました。ご参考まで。
以下、補足です。
このツール群は、3つのツールから構成されており、使うのが少し面倒です。以前は、DIGAから番組一覧を取得する手段としてDeveloper Toolsしか無いと思っていたので、こうなっています。しかし、今になって考えてみると、Node+Seleniumを使えば、1つのツールで全てできますね。ただ、自分で使う分には、特に不便を感じていないので、当面は、今のままの予定です。
補足2。
下記は、今回書き加えた部分の説明を補完する図です。
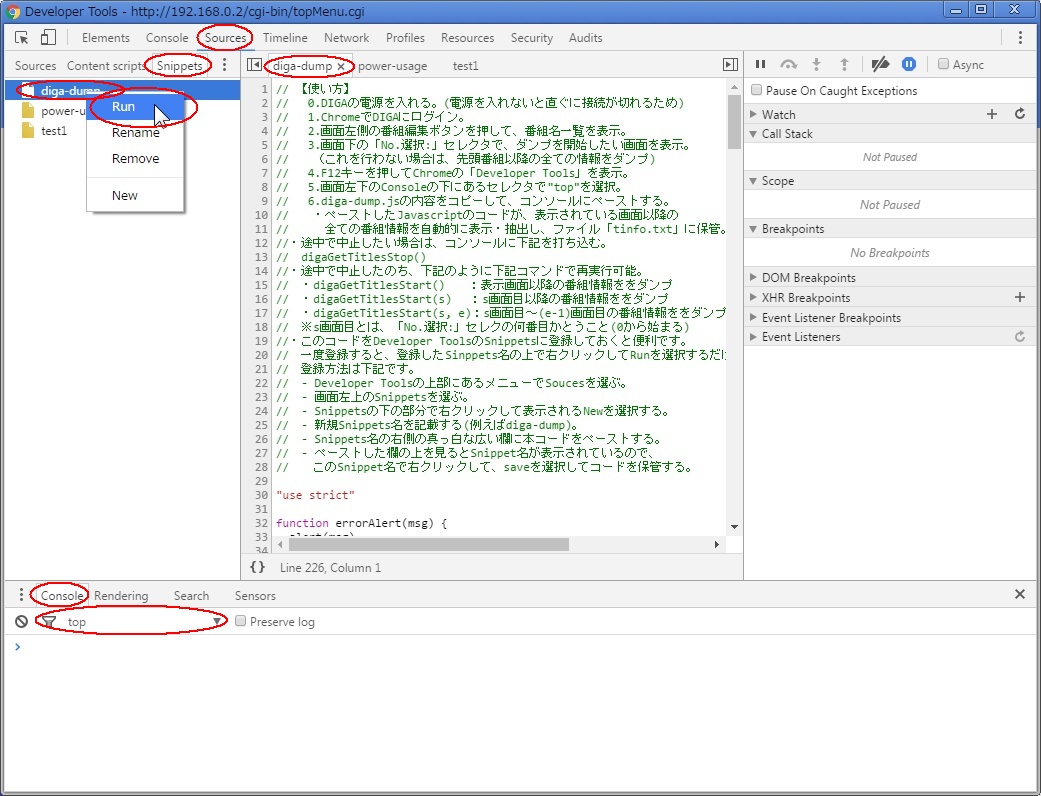
「みんなのPython勉強会」で頂いたESP8266にハマってます
Pythonの勉強会があると知り、先週参加しました。この勉強会は、Pythonの初心者から熟練者まで、色々な人が集まる会とのこと。今回は、「Pythonデータサイエンス祭り」と題し、Pythonで機械学習を活用するための進め方を中心に紹介されました。非常にタメになる内容でした。
みんなのPython勉強会
勉強会には100名以上の人が参加し、非常に活況でした。参加申し込みが定員の1.5倍程度あり、私は参加申し込みが遅かったために、当初、補欠扱いでした。参加できるか気を揉んでいましたが、結局、多数のキャンセルが出て、勉強会開催の5分前に参加できることが決まりました。
主催者側のご説明によると、3月に、Googleの人工知能AlphaGoが、韓国のイ・セドル氏(世界で一番強いと考えられている囲碁プレーヤー)に完全勝利したことをきっかけに、Pythonへの関心が高まっているとのこと。Pythonが機械学習の主流プラットフォームになっていること、および、AlphaGoをきっかけに世界各国でAIに対して数兆円規模の研究開発投資が始まり、日本の各企業でも、AI基盤としてPythonへの関心が高まっているようです。
勉強会のセミナー終了後に開催された懇談会で参加者数名と話したところでは、企業各社で、Pythonや機械学習の様子を見に来ているようでした。
MicroPython on ESP8266:頂きました
実は、懇親会で行われたLightning talkで、MicroPython on ESP8266の紹介がありました。ESP8266は、秋葉原で500円ほどで売っているWiFiモジュールです。マイクロプロセッサとFlash ROMも付いており、これにMicroPython(Pythonのサブセット)を移植した方がいて、発表者の方も試しに載せてみたとのこと。発表後に、太っ腹にも、2個のESP8266(MicroPython付)を、勉強会参加者にプレゼントするとのこと。興味があったので、ジャンケン大会に参加・勝利し、1つ頂きました。
MicroPython on ESP8266:起動
家に帰って、ESP8266の結線方法やMicroPythonの使い方などを調べたり、起動に必要な電源や線など用意するために数時間掛ってしまいましたが、無事、起動することができました。下記は、起動後に、テスト用のプログラムを入れて試したものです(素数生成プログラムを書いてみました)。

なお、上記に記載しましたように、ESP8266は、マイクロプロセッサ、Flash ROMにWiFiが付いたもので、GPIOなどの入出力端子や、AD変換端子もついてます。これに、色々なセンサーを付けてIoTに使うことを想定しているらしいです。通常の消費電流は80mAですが、DeepSleepモードでは1mA以下になります。また、内臓タイマーを使って、一定時間後にDeepSleepから復帰させることができます。
DeepSleepを使って、通常動作時間を1日に2分程度に留め、後はDeepSleepモードにしておけば、単3電池数本で、1年ぐらいは使えると思います。概算ですが、単三電池は約800mAh。80mAで10時間使える計算なので、1日2分しか使わなければ、300日使えということです。ちなみに、これとは別ですが、実は、ガラケーを目覚まし代わりに使っており、目覚ましで起きたら電源を切るようにしてます。動作時間は1日10分程度にしているおかげで、3カ月以上、バッテリーが持っています。
ESP8266周りの配線
勉強会でのプレゼンによると、通常、配線にはブリットボードというモノを使うらしいですが、手近になかったので、以前に買ったワニ口クリップにビニール線を半田付けして作った、急ごしらえの線で繋ぎました。(ちなみに、非常に扱い難いので、ブリットボードをAmazonで別途注文済)

なお、結線方法を図にしてみましたので、トライする方は参考にしてください。ちなみに、I016端子とRST端子の結線により、タイマーでDeepSleepモードから復帰できます。また、MicroPythonから、DeepSleepモードを制御することができます。MicroPython on ESP8266は、Flash ROM上にmain.pyというファイルがあると、起動後に自動的に実行するようになってます。そこで、main.pyで定期的にセンサーからデータを集めて、直ぐにDeepSleepするようにすれば、IoT端末として長期間使えると思います。

ちなみに、電源および信号線となるUSB-UART変換器は、202HWを改造したときに買ったものがあり、流用できました。Web掲載の記事によっては、ESP8266が170mAも消費するので、別途、3.3V電源を繋げないと動作しないと書かれていたのですが、幸い、既に持っていたUSB-UART変換器(400円で購入)で、電源容量が間に合ったようです。
なお、色々と試したところでは、WiFiを使っても、USB側では0.08Aしか流れていなので、3.3V側も、170mAは行かないと思います。参考までに、USB側の電流を測定中の写真を載せます(赤で0.08Aと表示)。

なお、上記写真では、ESP8266にソケット的なものが刺さってますが、このソケットは、家にあった廃材(PCキーボード、マウス)から引っぺがしたものです。
MicroPython再インストール
上記で、「Flash ROMにmain.pyが載っていれば」と書いたのですが、実は、頂いたものでは、Flash ROM上にファイルシステムが構築されていませんでした。MicroPythonのサイトを見ると、Flash ROMの容量が1MB以下の場合は、ファイルシステムを作らないとのこと。
頂いたESP8266のFlash ROMの容量が中々わからなかったのですが、データシートをよく見たところ、4MB入っていることが分かりました。そこで、GitHubからソースコードを入手して、MicroPythonを再インストールすることしました。
まずは、VirtualBoxでUbuntu環境を用意
MicroPythonを再インストールするには、Linux環境が必要で、Ubuntuが良さそうでした。これが無かったので、VirtualBoxでUbuntu 14.04の環境を構築しました。
UbuntuにOpenSource ESP SDKをインストール
MicroPythonのGitHubでの説明に従って、まずは、UbuntuにOpenSource ESP SDKをインストールしました。ここで少しトラぶりました。下記だけでうまくいくはずなのですが、make中に「Python missing or unusable error」というエラーが出て止まってしまいます。
$ sudo apt-get install make unrar autoconf automake libtool gcc g++ gperf \
flex bison texinfo gawk ncurses-dev libexpat-dev python python-serial sed \
git unzip bash help2man
$ git clone --recursive https://github.com/pfalcon/esp-open-sdk.git
$ cd esp-open-sdk
$ make
# install途中にエラーこれに関しての対応方法は、ここに書かれていました。書かれた内容に従って下記のようにしたところ、うまくいきました。
$ sudo apt-get install python2.7-dev $ sudo apt-get install python3.4-dev $ make
make完了後は、buildで作成されたbinディレクトリ(~/esp-open-sdk/xtensa-lx106-elf/bin)をPATHに追加する必要があります。
MicroPythonをmake
これは、GitHubの説明に従って下記のようにするだけでうまくいきました。
$ git clone https://github.com/micropython/micropython.git $ cd micropython/ $ git submodule update --init $ cd esp8266/ $ make axtls $ make
UbuntuからCOM5が見えるようにする
MicroPythonをESP8266に書き込むためには、Ubuntuの載った仮想マシンから
USB-UART変換器経由でCOM5に接続する必要があります。これに関しては、この記事が参考になりました。つまり、USB-UART変換器でWindowsから見えるようになるCOM5をVirtualBoxに繋ぐのではなく、USB-UART変換器自体がUbuntuから見えるように、VirtualBoxでUSB機器としての接続設定をするということです。
一番迷ったのは、USB-UART変換器のドライバの入手方法です。いろいろ調べたのですが、実は、何もしなくても、Ubuntuが自動的に認識していることが分かりました。下記は、dmesgコマンドで確認した結果です。
$ dmesg ... [ 248.778569] usbserial: USB Serial support registered for cp210x [ 248.778638] cp210x 2-2:1.0: cp210x converter detected [ 249.174198] usb 2-2: reset full-speed USB device number 3 using ohci-pci [ 249.670905] usb 2-2: cp210x converter now attached to ttyUSB0
MicroPythonをESP8266に書き込み
最初に、flashをeraseした方が良いとのこと。これに必要なesptool.pyは、「~/esp-open-sdk/xtensa-lx106-elf/bin/esptool.py」にあります。そこで、「~/esp-open-sdk/xtensa-lx106-elf/bin/esptool.py」へのシンボリックリンクを「~/micropython/esp8266/」に置き、下記コマンドで、USB-UART変換器が繋がっていることを確認してから、fashをeraseしました。(/dev/ttyUSB0は、USB-UART変換器のデバイスファイルです)
$ sudo ./esptool.py --port /dev/ttyUSB0 chip_id Connecting... Chip ID: 0x00eexxxx $ sudo ./esptool.py --port /dev/ttyUSB0 erase_flash Connecting... Erasing flash (this may take a while)...
ところが、一度eraseすると、UbuntuからUSB-UART変換器が見えなくなってしまいます。そこで、再度、VitualBoxの設定を変えて、UbuntuからUSB-UART変換器が見えるようにする必要がありました。
次に肝心の書き込みですが、Makefileでは、flash ROMのサイズが8Mbitと想定しているため、これを32Mbit(4MB)に変える必要があります。また、sudoでmake deployすると、esptool.pyのパスが認識されないため、これも修正が必要です。結局、次のように修正しました。
# Makefileのサイズ修正、パス修正
$(Q)./esptool.py --port $(PORT) --baud $(BAUD) write_flash --flash_size=32m 0 $<
#$(Q)esptool.py --port $(PORT) --baud $(BAUD) write_flash --flash_size=8m 0 $<後は、次のようにデプロイして完了です。
$ sudo ./esptool.py --port /dev/ttyUSB0 chip_id Connecting... Chip ID: 0x00eexxxx $ sudo make PORT=/dev/ttyUSB0 deploy Use make V=1 or set BUILD_VERBOSE in your environment to increase build verbosity. Writing build/firmware-combined.bin to the board Connecting... Erasing flash... Took 3.22s to erase flash block Wrote 505856 bytes at 0x00000000 in 59.6 seconds (67.9 kbit/s)... Leaving... $
その後
ファイル操作モジュール(pos.py)作成
上記までで、flash ROMに書き込めるようになったのですが、OSが無いため、「ls」「cd」「mkdir」「pwd」「cp」「mv」「rm」といったコマンドがなく、不便を感じました。また、Pythonのプログラムをflash ROMに書き込むには、プログラムを一度、文字列として変数に入れて、次のようなプログラムを打ち込んで書き込む必要があり、これも不便でした。
# 予め、変数sにプログラムの文字列を入れておく >>> with open("test.py", "w") as f: ... f.write(s)
そこで、OSの非常に基本的な機能を、ある程度Linuxライクに使えるように、簡単なモジュールを作成しました。実は、MicroPythonには、「uos(Micro OS)」というモジュールが入っていて、importすると使えるのですが、関数の名称がLinuxと結構異なり、機能も不足しているので、これを補うためのモジュール「pos(Pico OS)」を作成しました。GitHubに置きましたので、中身を見たうえで、良かったら使ってください。
ちなみに、ESP8266は、RAMが50KBしかなく、MicroPythonが起動した状態では、22KBしか残っていません。そのため、色々なモジュールをインポートすると、RAMが結構減ってしまいます。これは気を付けてください。
起動後に定期的に出るメッセージの抑止方法
ESP8266を起動すると、定期的に下記のようなメッセージが表示されます。これは害がないとのことですが、邪魔になるので、下記により抑止できます。
# 表示されるメッセージ例 chg_A3:0 chg_A3:-180 chg_A3:0 chg_A3:-180 chg_A3:0 chg_A3:-180 # 抑止方法 >>> import esp >>> esp.osdebug(None)
WiFi接続方法
次のプログラムをflash ROMのファイルに入れておけば、これをimportして、do_connect()を呼び出すことで、WiFiに接続できます。
def do_connect(): import network sta_if = network.WLAN(network.STA_IF) if not sta_if.isconnected(): print('connecting to network...') sta_if.active(True) sta_if.connect('無線LANルータのSIDを記載', '無線LANルータのパスワードを記載') while not sta_if.isconnected(): pass print('network config:', sta_if.ifconfig())
WiFiの状態確認と停止の方法は下記です。
>>> wlan.ifconfig() # 状態確認 >>> wlan.active(False) # WANの停止
なお、一度WiFiで繋ぐと、次回起動時に、勝手にWiFiに繋がります。MicroPythonよりも下のレイヤーで、WiFiの設定を覚えており、自動的に繋ぐようです。
MicroPython on ESP8266の性能
性能測定のために下記の素数生成プログラムで試しました。1000までの素数の生成「gen_primes(10000)」で7秒ぐらい掛っています。ちなみに、2年前に買ったWindows PC上で測定したところ6.6ミリ秒だったので、1000倍ぐらい遅いですね。ただ、センサーのデータを取得するぐらいならば問題ないでしょう。
# MicroPythonで走らせたプログラム import machine rtc = machine.RTC() rtc.datetime((2016, 6, 8, 0, 15, 35, 0, 0)) from math import sqrt def gen_primes(n): primes = set([2, 3, 5, 7, 11, 13, 17, 19]) for i in range(23, n+1, 2): for j in range(3, int(sqrt(n))+1, 2): if i % j == 0: break else: primes.add(i) return primes import gc def sec(): dt = rtc.datetime() return (dt[4]*60 + dt[5])*60 + dt[6]+ dt[7]/1000.0 def time_gen_primes(n): a1 = gc.mem_alloc() s1 = sec() f1 = gc.mem_free() g = gen_primes(n) a2 = gc.mem_alloc() s2 = sec() f2 = gc.mem_free() print("gen_primes({}):{:.3f} sec, len:{}, alloc:{}, free:{}".format(n, s2 - s1, len(g), a2, f2)) g = None gc.collect() for n in range(1000, 30000, 1000): time_gen_primes(n)
PCでは以下のように測定。
# ファイル:gen_primes.py from math import sqrt def gen_primes(n): primes = set([2, 3, 5, 7, 11, 13, 17, 19]) for i in range(23, n+1, 2): for j in range(3, int(sqrt(n))+1, 2): if i % j == 0: break else: primes.add(i) return primes # 下記コマンドで測定。表示されるのは1000回の秒数なので、1回あたり6.6ミリ秒程度。 >>> import timeit >>> timeit.timeit("gen_primes(10000)", setup='from gen_primes import gen_primes', number=1000) 6.574487369428709
今後
MicroPython on ESP8266を、IoTデバイスとして色々試したいと思っています。しかし、現状では配線がごちゃごちゃして扱いにくいので、USBで直結できるコンパクトなものをAmazonで買うことにしました。既に発注済みですが、中国から国際便で送られてくるために、届くまでに1~2週間くらい掛り、届くのは6月26日の予定です。
![HiLetgo NEW NodeMcu Lua ESP8266 CH340 WIFI インターネット 開発ボード 最新ファーム・ウエア [並行輸入品]](http://ecx.images-amazon.com/images/I/51NIMSO8CfL._SL160_.jpg "HiLetgo NEW NodeMcu Lua ESP8266 CH340 WIFI インターネット 開発ボード 最新ファーム・ウエア [並行輸入品]")
HiLetgo NEW NodeMcu Lua ESP8266 CH340 WIFI インターネット 開発ボード 最新ファーム・ウエア [並行輸入品]
- 出版社/メーカー: HiLetgo
- メディア: おもちゃ&ホビー
- この商品を含むブログを見る
これに繋げるセンサーや、電源となるDC-DCコンバーター(電池から3.3Vに直接変換するため)、色々な配線など、ハード系の部品をAmazonで色々注文し、届くのを待っているところです。
Amazonで中国系の会社から部品を購入すると、届くまで時間が掛りますが、非常に安くて気軽に試せるので、これからも色々購入して試したいと思っています。
MicroPython on ESP8266を契機に、IoTのハードとソフトに興味を持ち始めた、今日この頃です。
Python チュートリアルをIPython Notebook形式に変換
前回記事で、Python チュートリアル(2.7系)に記載のプログラム例を、スクリプトとして抜き出しましたが、今回、これにチュートリアルの文章も追加し、Jupyter/IPython Notebook形式に変換しました。
これで、チュートリアルの文章も見ながら、各プログラム例の修正・試行が簡単にできるようになりました。Python初心者の型は、ぜひご活用ください。(私も、Python初めて1週間ぐらいの初心者ですが..)
Jupyter/IPython Notebook形式への変換は手動なので、誤りも結構あると思います。誤りがったら、適宜修正頂けると大変ありがたいです。Pythonの日本サイトに係る方がいらっしゃいましたら、このファイル群を引き取って活用いただけると大変ありがたいです。
なお、保管場所は、前回とは異なり、下記になります。
Pythonチュートリアルプログラム例スクリプト化(全面改訂)
TensorFlowの勉強に必要なDocker導入サバイバルメモ
前回の記事でGoogleのTensorFlowで勉強を始めたことを書きましたが、これにあたっては、Pythonより前に、TensorFlowの学習環境が詰まったDockerイメージを動かすためのDocker環境を構築する必要がありました。Dockerについて、名前は聞いていたものの、使ったことがなかったので、今回初めて使いました。TensorFlowの勉強を始めたいがDockerは知らない人の参考になれば幸いです。
Dockerとは
コンテナ (起動が超速い)
VitualBoxやVagrantと、Dockerの特性の違いがよく分かっていなかったのですが、Dockerは、サーバ仮想化自体は不要です。DockerはLinuxマシン上で、ファイルシステムやプロセスID、ホスト名、ユーザ/グループなどを仮想化して隔離した環境「コンテナ」を提供するもの。このコンテナで動いているプロセスは、独立したLinux環境で動いているプロセスのように動作します。
実際、Dockerでコンテナを動作させると、コンテナの外でpsコマンドを実行すると、コンテナ内で動いているプロセスが見えます。このプロセスのPIDは通常のユーザプロセスと同様に1以外ですが、コンテナ環境内でpsコマンドでみると、同じプロセスがPID=1になっているように見えます。
VirtualBoxやVagrantでOSイメージを起動する場合は、それなりの時間がかかりますが、コンテナは、単にPIDなどの環境を仮想化してLinuxプロセスを起動するだけなので、一瞬で起動が完了します。
コンテナイメージの差分管理 (ストレージ量、転送量を削減)
コンテナで使うファイルシステムは、DebianやUbuntuなどのシステムイメージ(Read Only)をベースに、後から書き込んだ部分は差分として管理されています。つまり、ベースイメージはRead Onlyで、その上にWritableな層が重なる感じです:

ネット上のDockerイメージhubであるDocker hubでも、イメージが差分管理されており、Docker hubからコンテナイメージを取ってくる場合は、必要な差分のみが取得されます。つまり、あるコンテナイメージ(Aとします)がUbuntu 14.04(718MB)の上に300MBの差分を書き込んで作成されている場合、ローカルなリポジトリにUbuntu 14.04のコンテナイメージがあれば、差分である300MBのみを自動的にダウンロードしてコンテナイメージAが構築されます。
逆に、Ubuntu 14.04ベースに自前で構築したコンテナイメージをDocker hubにcommitする場合も、差分のみがアップロードされます。
WindowへのDockerの導入
詳しくはDockerのWindowsへの導入ガイドを見ていただくのが良いですが、基本的には、ダウンロードしてダブルクリックして、インストールするだけです。
DockerにはLinux環境が必要なので、Dockerのインストールでは、Windwos上でLinux環境を動かすための基盤としてVirtualBoxが自動的にインストールされます。既にVirtualBoxをイントール済みの場合は、インストールの途中で出てくる画面で、VirtualBoxのチェックボックスをOffにしておけば大丈夫です。
Docker関連のコマンドの一部はshスクリプトになっているため、上記に加え、shスクリプトの基盤としてgit bashも導入されます。
上記記載のLinux環境は、下記の図の「DOCKER_HOST」の部分になります。git bashは「クライアント」部分に相当します。
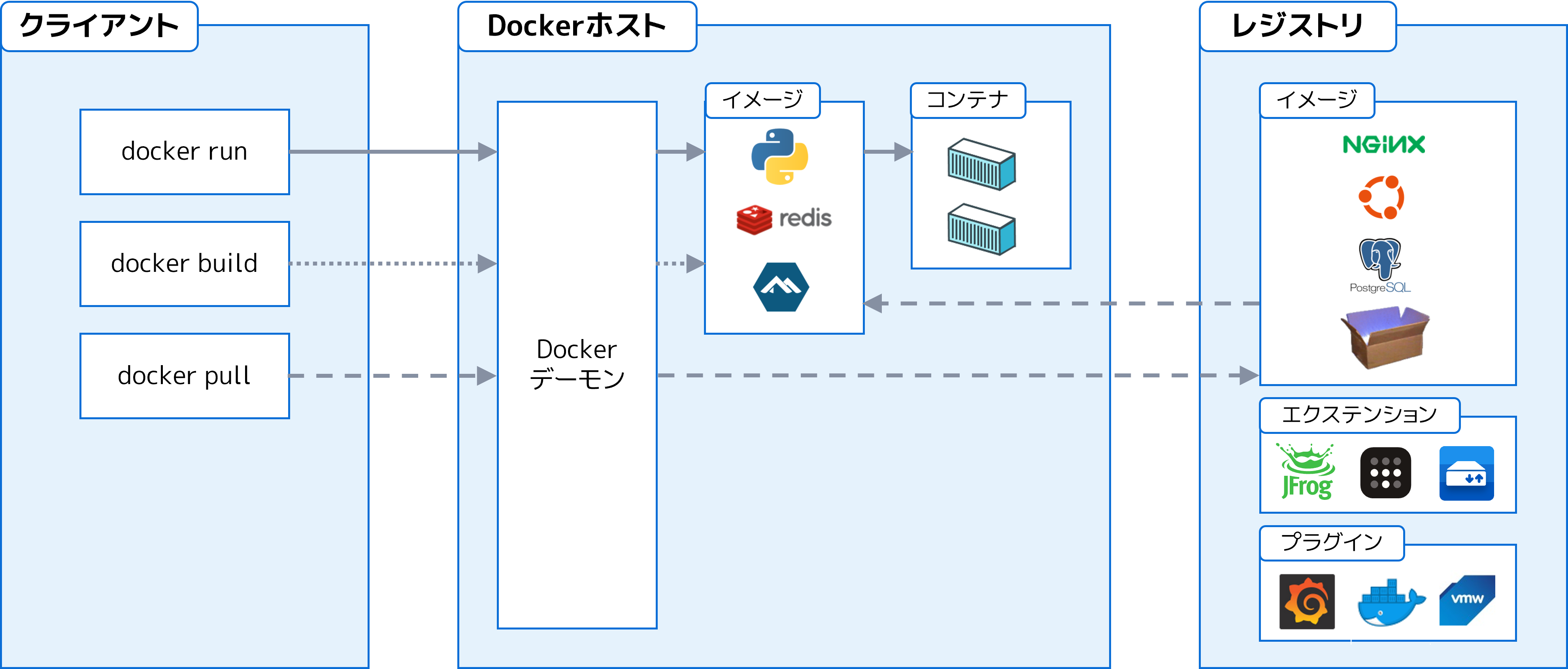
使い方(TensorFlowを使うのに必要な要点のみ)
Docker ToolboxのインストールでWindowsのデスクトップに追加されたアイコン「Docker Quickstart」をクリックすると、クライアントであるgit bashの画面が開き、まだDOCKER_HOSTが起動していない場合は、VitualBoxでHeadless起動し、起動完了後に、プロンプトが出ます。
なお、DOCKER_HOSTの割り当てメモリ量はVirtualBoxで確認できますが、1GBになっています。これを増やすには、こちらの記事を参照願います。TensorFlowを試すには、メモリ量の追加が必須です。
なお、TensorFlowのチュートリアルでは、下記コマンドでDockerコンテナを起動するように書かれていたので、Dockerをインストール後にDockerのドキュメントをほとんど見ずに、下記コマンドでコンテナを起動していろいろ試してました。
$ docker run -p 8888:8888 -it --rm b.gcr.io/tensorflow-udacity/assignments:0.5.0
しかし、git bashの画面で"control-c"を打って、コンテナを止めたら、作業結果が全て失われていました。上記コマンドの、「-rm」オプションは、コンテナが止まったら差分データを破棄するというオプションでした。TensorFlowのチュートリアルは、一度に終わるわけではないので、「-rm」は付けずに起動してください。
また、メモリ量を増やしたり、名前を付けたほうが良いので、下記のように起動するのが良いです。(メモリ量は6GB、コンテナ名はtensorflowとした場合)
$ docker run -p 8888:8888 -it -m 6g --name tensorflow b.gcr.io/tensorflow-udacity/assignments:0.5.0
「-rm」オプションをつけなければ、一度起動したコンテナは、消すまでずっと保管されます。これを見るには、下記コマンドを使ってください。
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS
PORTS NAMES
89d7c3554b2a itsukara/my-tensorflow-udacity:1.0 "/run_jupyter.sh" 10 hours ago Exited (137) 5 seconds ago tensorflowすでに作られたコンテナを再起動するには、下記のようにします。なお、下記では、画面上に何も出さずに起動しています。
$ docker start tensorflow tensorflow
これを止めるには、下記のようにします。
$ docker stop tensorflow tensorflow
すでに動いているコンテナにログインするには、下記のようにします。TensorFlowを試すと、途中で非常に大きなファイルが作られるので、これを削除したりする際に、下記でログインすると良いです。ちなみに、「-it」オプションは、起動したプロセスとインタラクティブに接続するために必要です。
$ docker exec -it tensorflow /bin/bash root@89d7c3554b2a:/notebooks#
よく使いそうなコマンド一覧を下記に記載しました。詳細を見たい場合は「docker --help」「docker run --help」などのコマンドで確認願います。
docker run コンテナ名イメージ名 # 新たにコンテナを起動 docker start コンテナ名/コンテナID # 停止したコンテナを再起動 docier stop コンテナ名/コンテナID # 起動中のコンテナを停止 docker ps # 現在起動しているコンテナの一覧を見る docker ps -a # 既に停止したコンテナも含めて一覧を見る docker exec -it コンテナ名 bash # 起動中コンテナへの接続 docker rename コンテナ名/コンテナID 新コンテナ名 # コンテナ名変更 docker rm コンテナ名 # コンテナ削除 docker images # コンテナイメージ一覧表示 docker rmi コンテナイメージ名 # コンテナイメージ削除 docker logs コンテナ名/コンテナID # コンテナのログ表示 docker commit コンテナ名/コンテナID リボジトリ名 # リポジトリへの登録
参考
ちなみに、Windowsでは、DOCKER_HOSTの仮想イメージファイルは下記に作られます。最大20GBまで増えますので、Cドライブの容量が少ない方はご注意願います。(当方は13GBぐらいまで増えています)
C:\Users\ユーザ名\.docker\machine\machines\default <|| ** 補足
Pythonチュートリアルのプログラム例をスクリプト化
囲碁の世界チャンピオンがAlphaGoに勝ったのは凄いですね。昔のAIは大したことしかできませんでしたが、ここ数年の進歩は目覚ましいものがあると思っています。各国・各企業・教育機関でも、AlphaGOをきっかけに、機械学習の研究・開発・利用に拍車がかかっていると思います。機械学習は個人的に非常に興味が湧いたので、勉強を始めることにしました。(最先端のことでも投資無しで簡単に始められる現在のネット状況に感謝)
早速、AlphaGoに強く関係しそうなGoogleのTensorFlowに関し、GoogleがUDACITYで提供している無料講座で勉強を始めました。無料講座では、機械学習に関する色々な概念の説明の後、実際にTensorFlowの使い方を試します。その段階になって、Pythonのプログラムが分からないことに気が付きました。Pythonを知らなくても、コンピュータ言語の一種なので何とかなるだろう思っていたのですが、やはり、Pythonのチュートリアルぐらいは終わらせてから、チュートリアルの戻ることにしました。
Pythonの入門講座に関しWebで色々と探したところ、Pythonは米国の教育機関で広く活用されているおかげか、情報やライブラリが充実しており、日本語化もされていることが分かりました。さっそく、日本語版のチュートリアルを読んで勉強しました。その際に、チュートリアルに載っているプログラム例を、スクリプトとしてファイルに抜き出して試しましたので、その結果をGitHubで公開することにしました。
README.mdの抜粋
Python チュートリアルに記載された対話形式でのプログラム実行例から、実行結果を削ってスクリプト部分だけを抜き出し、対話モードではなくファイルとして実行できるようにしたものです。
対話モードでは入力した内容が失われ、再入力が面倒だったりするので、一度ファイルに記載してから実行したいと思いました。そこで、対話形式のプログラム例からスクリプトを抜き出してファイルにしました。なお、対話モードでは、入力した式を評価した結果が表示されますが、コマンドプロンプトからファイルを実行した場合は式の評価結果が表示されないので、一部「print」文を追加しています。
また、ファイルを実行した際に、プログラム例の内容と実行結果が一緒に出力されるようにしています。この目的で、print_and_exec.pyというモジュールを作りました(数行ですが)。例として、次のように記載すると、スクリプトの内容と実行結果が出力されます。また、例外が発生する部分は、try_exec("実行スクリプト")という形で書いておくと、そこで実行が止まらず、例外発生結果が出力されます。
# print_and_exec_example.py # coding: UTF-8 from print_and_exec import * print_and_exec(ur''' "■コード例の説明" "以下、Pythonのスクリプトを記載" print "hello world" try_exec('raise TypeError("Wrong type")') ''')
上記実行結果は下記です。
===========================================================
【スクリプト】
"■コード例の説明"
"以下、Pythonのスクリプトを記載"
print "hello world"
try_exec('raise TypeError("Wrong type")')
【実行結果】
hello world
Error:TypeError('Wrong type',)自分の学習用に取り纏めたものなので、一部のプログラム例は抜けていたりします。また、自分の理解を深めるために独自のプログラム例を加えたりしています(ch9のComplex classなど)。また、プログラム例で参照するファイルも追加しています(ファイル入出力、パッケージの部分など)。
ご参考まで
Java SE 8 Programmer I (Silver)に合格しました
本日、Oracleの認定試験「IZO-808-JPN Java SE 8 Programmer I」を受験し、めでたく合格することができました。これで、「Oracle Certified Java Programmer, Silver SE 8」の資格が取れました。
資格取得の経緯
Javaは、6年ぐらい前に、ドイツの方が作ったSUDOKUプログラムを改造する際に、見よう見まねで使いました(関連記事)。しかし、改造は場当たり的に行ったので、Javaの文法は勉強していませんでした。現在、再就職活動中で色々な転職フェアに行っているのですが、会場ブースで話を聞くと、色々な人が「Javaは必須」と言っていました。そこで、再就職に少しでも役立つように、Javaの資格を取ることにしました。4/20にJavaの問題集兼解説書を買って、問題を解きながらJavaの勉強をしていました。
解説本/問題集の選択
解説本/問題集を買うにあたっては、解説本と問題集を別々に買うか、両方を1冊にしたものを買うか、結構迷いました。本屋で色々な本を比較してみたのですが、両方を一緒にした下記の本の方がコストパフォーマンスが良く(2冊別々に買う場合の約半額)、内容も分かりやすく(問題を解くことで「自分は何が分からないか」がよく分かる)、これにしました。
![徹底攻略 Java SE 8 Silver 問題集[1Z0-808]対応](http://ecx.images-amazon.com/images/I/51B0H%2BURtOL._SL160_.jpg "徹底攻略 Java SE 8 Silver 問題集[1Z0-808]対応")
徹底攻略 Java SE 8 Silver 問題集[1Z0-808]対応
- 作者: 志賀澄人,株式会社ソキウス・ジャパン
- 出版社/メーカー: インプレス
- 発売日: 2016/01/18
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
問題集/解説本の使い方
本日の試験では、全77問のうち、10問弱は、上記問題集のものがそのまま出て、かなり役立ちました。ただ、解説を読んだだけでは納得できないこともあったので、Eclipseで実際にプログラムを書いて、いろいろ試して、納得しながら勉強を進めました(関連記事1、関連記事2)。特に、abstractやinterfaceは、理解するのに骨が折れました。
進め方としては、問題を一度解いてみて(最初は分からないことが殆ど)、解説を読んで勉強し(一度躓いてから読むので記憶に残りやすい)、後でもう一度問題を解く方法で進めました。この問題集は、最初は基本的なことが多く、後の方に進むにつれて、内容が難しくなっていく書き方なので、基礎を積み重ねながら、順次、新たなことを学ぶという感じで、結構、気持ち良く勉強することができました。ただ、ある程度勉強すると、体系的にまとまった内容が知りたくなりましたが、そのような点に関しては、残念ながら不足していると思います。そこで、体系的な理解は、Javaのドキュメントを見て補いました。
正答率の合格ライン
おかげさまで、正解率は94%(77問中4問誤り)と、合格ライン65%を軽く超えることができました。それにしても、合格ラインが65%というのは、少し甘すぎる気がしますね。なんだか、自社の技術を知った技術者の数をできるだけ増やしたいという意図が見え隠れします。そういえば、5/24開催のJava Day Tokyoのオープニングで「Javaの技術者は全世界で1000万人いる」といってましたね。なお、これは杉原CEOの講演での数字であり、別の方(米国人)は900万人と言っていたと思います(USTREAMのライブ中継は翻訳や字幕がないので少し不確かですが)。
今後
現在、Goldも挑戦しようか迷っているところです。5/12にOracleが開催した「【オンライン限定】Oracle Certified Java Programmer, Gold SE 8 認定資格 試験対策ポイント解説セミナー」は一応見て、内容は大体わかりましたが... Goldは、内容が難しくなるだけでなく、問題数も増えます(77門が88問に増える。時間は同じ)。また、Gold SE 8の認定試験は昨年の12月に始まったばかりのため、上記問題集の「Gold SE 8対応版」が出ていないです。更に、「開発経験なしに資格だけ取り続けるのもどうなんだろう」との思いもあり、保留中です。
追記(2016/6/3)
テスト勉強という意味では上記で記載した本がとても役立ちましたが。体系的な学習という点では、下記の本の方が役立ちました。あまり深くは書かれていませんが、かなり幅広く、体系的、かつ、分かりやすく書かれており、Javaでの開発に係る全体像をつかむことができました。言語仕様以外の部分としては、非標準ライブラリの活用、外部資源へのアクセス(ファイル、ネットワーク、データベース)、効率的な開発の実現(開発ツール、単体テストとアサージョン、品質のメトリクスなど)、デザインパターンなどが書かれています。
")
スッキリわかる Java入門 実践編 第2版 (スッキリシリーズ)
- 作者: 中山清喬
- 出版社/メーカー: インプレス
- 発売日: 2014/09/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (7件) を見る