DeepMind社のAtariゲーム攻略論文のコード等を試行中
DeepMind社が有名になるキッカケとなった論文「Playing Atari with Deep Reinforcement Learningの内容を実装して試した記事「DQNをKerasとTensorFlowとOpenAI Gymで実装する」を、深層学習の輪講メンバーで読みながら、実際に実行させて試しています。
必要となる環境「KerasとTensorFLowとOpenAI Gymを載せたUbuntu 14.04 PC(16GB RAM + GTX760)」は整備が完了しており、ソースコードと共に、28時間学習済みのデータも公開されているので、学習結果をすぐに試すことができました。
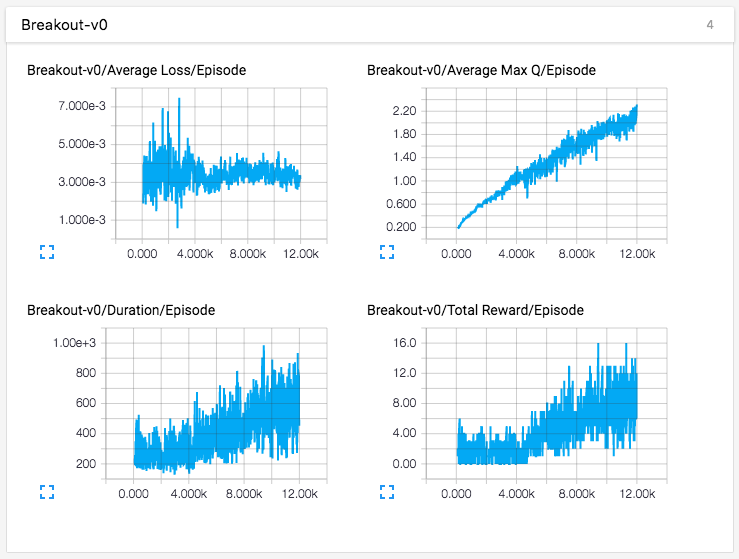
ただ、28時間の学習結果を使ってゲーム画面を表示させても、まだまだ動きが不自然で、SCOREがほとんど伸びません(玉が5個あり、点数は10点〜20点、つまり2〜4点/玉)。記事では、「もっと学習させれば、もっとうまくなるだろう」と書かれていたので、もっと長期間学習させてみました。下記がその結果です。

記事では1万2千エピソードの学習とのことだったので、3万エピソード学習させたのですが、残念ながら、途中(1万7千エピソードあたり)で頭打ちになり、その後、Max QもTotal Reward(SCORE)も、落ちてしまいました。学習には、2日以上掛かったのに、残念です。
なお、記事では、論文とは異なる部分もあったので、その部分は、論文に合わせて修正しました。具体的には下記の部分です。
- ゲーム画面の加工
- 論文では、ゲーム画面(210x160ピクセル)を、グレースケールに変換し、110x84にスケーリングした後、ゲームの主要部分である84x84の領域を抜き出しているのですが、記事では、抜き出さずに、直接84x84にスケーリングしていました。そこで、この部分は、論文通りに修正しました。
- ネットワークの構成
- 論文では、サイズが8x8のフィルター16個、4x4のフィルター32個、全結合256ノードを使っているのですが、記事では、8x8のフィルター32個、4x4のフィルター64個、3x3のフィルター64個、全結合512ノードになっていたので、論文通りに修正しました。
この修正が、学習状況に影響した可能性はありますが、1万2千エピソードあたりまでのグラフは記事(下記)とそっくりなので、記事のままのコードで試しても、おそらく頭打ちになるのではないかと思っています。なお、ネットワーク構成が記事よりも簡単になっているので、手持ちのマシンでの学習速度は、少し速くなりました。
感想
この試行のために、部屋のエアコンを2日間もつけっぱなしにし、デスクトップPCも本実験専用に使っていました。そのため、電気代が心配になり、また、デスクトップPCが使えず不便でした。
機械学習は、個人で持っているPCで学習を試行するのは厳しいですね。学習結果を使うだけならばマシンパワーは使わないので、問題ないですが...
その後
DeepMind社は、上記論文の後も、いろいろな論文を出しており、ここに公開しています。
その中で、学習速度がDQNよりも格段に速い方法(A3C)が「Asynchronous Methods for Deep Reinforcement Learning」に書かれており、その内容を実装したコードを、いろんな人がGithubで公開しています。
その中で、下記2つが良さそうに思えたので、これらを試行できる環境を整備しました。
1つ目は、学習結果のデータ(ブロック崩し(Breakout)とインベーダーゲーム(Space Invaders)も公開しているので、ゲーム画面を表示して試してみました。
DQNの記事のコードとは異なり、人間ならば中級程度の動きをしています。学習も試してみようとしたのですが、36CPUで18時間掛かるコードであり、4CPUしかない手持ちのマシンでは、180時間くらい掛かりそうです。実際に少し走らせてみたところ、Githubにか書かれた記事での処理スピード1300step/秒(計算値)と較べて、手持ちマシンでは80step/秒程度であり、計算上は280時間(12日間弱)も掛かりそうです。そのため、これを試すのは諦めました。
2つ目は、学習結果のデータが公開されていませんが、実験環境が個人のPC相当であり(i7 6700 + GTX980Ti)、16時間ぐらいで、かなりのSCOREが出るとのこと(下記)。

実際に試したたところ、Githubの記事に書かれた学習スピード(416steps/秒、A3C-LTSM)と較べて、手持ちのマシンでも375steps/秒出ているので、計算上は、手持ちのマシンで18時間程度かければ、記事の16時間ぐらいの学習ができそうです(学習スピードと、学習完了までの予測時間を表示するコードを追加して試してます)。現在、これをトライ中であり、結果が出たら、記事を書く予定です。また、その後、記事で扱っているゲーム(ポン(Pong))以外のゲームで試そうと思っています。具体的には、ブロック崩し(Breakout)で試す予定です。