
Deep Learning最新論文の再現コードを試行(DeepMindのA3C)
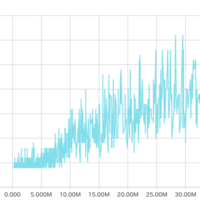
前回の記事で書きましたように、DeepMind社の最新論文Asynchronous Methods for Deep Reinforcement Learning、16 Jun 2016に書かれた手法A3C(Asynchronous Advantage Actor-critic)の再現コードをGithubで見つけたので、実際に走らせて試行中。 Pongの学習結果 約27時間(36.5M steps)の学習を行った結果が下記です。横軸…
